“Solr or Elasticsearch?”…well, at least that is the common question we hear from Sematext’s consulting services clients and prospects. Which one is better, Solr or Elasticsearch? Which one is faster? Which one scales better? Which one is easier to manage? Which one should we use? Is there any advantage to migrating from Solr to Elasticsearch? – and the list goes on.
These are all great questions, though not always with clear and definite, universally applicable answers. So which one do we recommend you use? How do you choose in the end? Well, let us share how we see Solr and Elasticsearch past, present, and future, let’s do a bit of comparing and hopefully help you make the right choice for your particular needs by rounding up the most important differences between Solr and Elasticsearch.

If you are new to Elasticsearch and Solr you might greatly benefit from reading our Elasticsearch Tutorial as well as Solr Tutorial.
Elasticsearch and Solr are two of the leading, competing open source search engines known to anyone who has ever looked into (open source) search. They are both built around the core underlying search library – Lucene – but they are different in terms of functionalities such as scalability, ease of deployment, as well as community presence and many more. Solr has more advantages when it comes to the static data, because of its caches and the ability to use an uninverted reader for faceting and sorting – for example, e-commerce. On the other hand, Elasticsearch is better suited – and much more frequently used – for timeseries data use cases, like log analysis use cases.
When it comes to choosing Solr vs Elasticsearch, each of them has its own set of strengths and weaknesses, so there’s no right or wrong. Although it seems that Elasticsearch is more popular, each may be a better or worse fit depending on your needs and expectations.
With Solr Monitoring agent, you can detect anomalies and set up threshold-based alerts to ensure peak Solr performance.
Learn about Solr monitoring See plans
Free for 14 days. No credit card required.
We hope this comparison of the two leading open source search engines provides enough information and guidance to help you make the right choice for your organization:
Comparing Solr vs Elasticsearch: What Are The Main Differences?
Both search engines are evolving rapidly so, without further ado, here is up to date information about the differences between Elasticsearch and Solr:
1. Apache Solr vs. Elasticsearch Engine Performance & Scalability Benchmark
Performance-wise, Solr and Elasticsearch are roughly the same. We say “roughly” because nobody has ever done good, comprehensive and unbiased benchmarks. For 95% of use cases either choice will be just fine in terms of performance, and the remaining 5% need to test both solutions with their particular data and their particular access patterns.
That said, if you have mostly static data and need full precision for data analysis and blazingly fast performance you should look at Solr.
You can also watch the video from two of our engineers – Radu and Rafał giving Side by Side with Elasticsearch & Solr Part 2 – Performance and Scalability (or you can check out the presentation slides) talk at Berlin Buzzwords. This talk – which included a live demo, a video demo and slides – dove deeper into how Elasticsearch and Solr scale and perform, the insights being valid today as they were back in 2015.
Radu and Rafal showed attendees how to tune Elasticsearch and Solr for two common use-cases: logging and product search. Then they showed what numbers they got after tuning. There was also some sharing of best practices for scaling out massive Elasticsearch and Solr clusters; for example, how to divide data into shards and indices/collections that account for growth, when to use routing, and how to make sure that coordinated nodes don’t become unresponsive.
With the tests mentioned in this video we saw that on static data Solr was awesome.
What’s more, compared to Elasticsearch, facets in Solr are precise and do not lose precision, which is not always true with Elasticsearch. In certain edge cases, you may find results in Elasticsearch aggregations not to be precise, because of how data in the shards is placed.
Elasticsearch Monitoring agent allows you to monitor key Elasticsearch metrics to get the most out of your cluster.
Learn about Elasticsearch monitoring See plans
No credit card required.
2. Age, Maturity and Search Trends
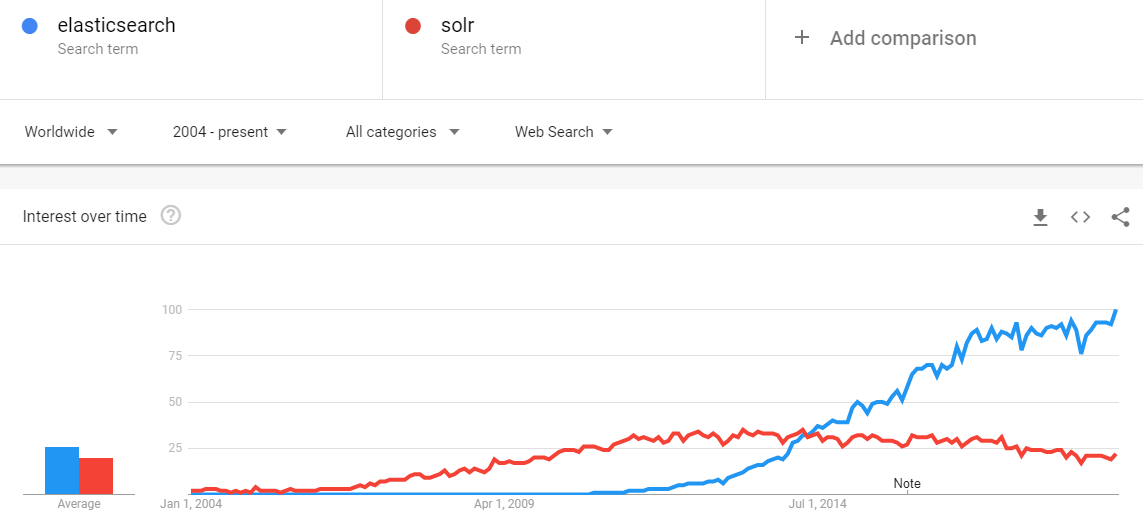
Solr is not dead. According to DB-Engines, both Elasticsearch and Solr are among the most popular in the developer community. Here are the latest usage stats that support this:
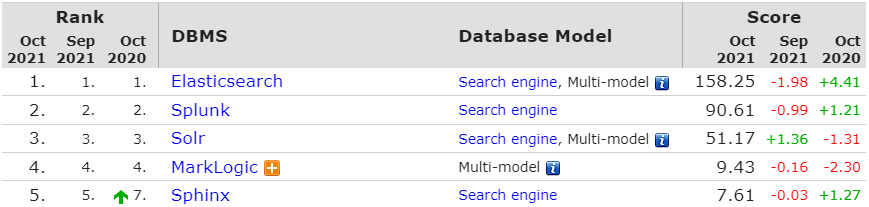
Apache Solr is a mature project with a large and active development and user community behind it, as well as the Apache brand.
First released to open source in 2006, Solr has long dominated the search engine space and was the go-to engine for anyone needing search functionality. Its maturity translates to rich functionality beyond vanilla text indexing and searching; such as faceting, grouping (aka field collapsing), powerful filtering, pluggable document processing, pluggable search chain components, language detection, etc.
Then, around 2010, Elasticsearch appeared as another option on the market. Back then it was nowhere near as stable as Solr, did not have Solr’s feature depth, did not have the mindshare, brand, and so on. But it had a few other things going for it: Elasticsearch was young and built on more modern principles, aimed at more modern use cases, and was built to make handling of large indices and high query rates easier.
Moreover, because it was so young and without a community to work with, it had the freedom to move forward in leaps and bounds, without requiring any sort of consensus or cooperation with others (users or developers), backwards compatibility, or anything else that more mature software typically has to handle. As such it exposed certain highly sought-after functionality (e.g., Near Real-Time Search) before Solr did.
Technically speaking, the ability to have NRT Search really came from Lucene, the underlying search library to both Solr and Elasticsearch use. The irony is that because Elasticsearch exposed NRT Search first, people associated NRT Search with Elasticsearch, even though Solr and Lucene are both part of the same Apache project and, as such, one would expect Solr to have such highly demanded functionality first.
Elasticsearch, being more modern, appealed to several groups of people and organizations:
- those who didn’t yet have a search engine and hadn’t invested a lot of time, money, and energy in its adoption, integration, etc.
- those who had to deal with large volumes of data and needed to more easily shard and replicate data (search indices) and shrink or grow their search cluster
Of course, let’s admit it, there will always be those who like jumping on new shiny objects, too.
Fast forward to 2022. Elasticsearch is no longer new, but it’s still shiny. It closed the feature gap with Solr and, in some cases, surpassed it. It certainly has more buzz around it. At this point both projects are very mature. Both have lots of features. Both are stable. We have to say, though, that we do see more Elasticsearch clusters with issues, but we think that is primarily because of a few reasons:
- Elasticsearch, traditionally being easier to get started with, made it possible for anyone to start using it out of the box, without too much understanding of how things work. That’s great to get started, but dangerous when data/cluster grows.
- Elasticsearch, lending itself to easier scaling, attracts use cases demanding larger clusters with more data and more nodes.
- Elasticsearch is more dynamic – data can easily move around the cluster as its nodes come and go, and this can impact stability and performance of the cluster.
- While Solr has traditionally been more geared toward text search, Elasticsearch is aiming to handle analytical types of queries, too, and such queries come at a price.
Although this may sound scary, let me put it this way – Elasticsearch exposes a ton of control knobs one can play with to control the beast. Of course, the key bit is that one has to be aware of all possible knobs, know what they do, and make use of that. For example, despite what you just read about Elasticsearch, we rely on it in our organization for several different products, even though we know Solr just as well as we know Elasticsearch.
Solr: Not Totally Eclipsed
What about Solr? Solr hasn’t exactly stood still. The appearance of Elasticsearch was actually great for Solr and its community of developers and users. Despite being almost 14+ years old, Solr development is going faster than ever. It, too, has a friendly API now. It, too, has the ability to more easily grow and shrink clusters, create indices more dynamically, shard them on the fly, route documents and queries, etc., etc. Note: when people refer to SolrCloud they specifically mean this form of very distributed, Elasticsearch-like Solr deployment.
We attended a Lucene/Solr Revolution conference in Washington, DC and were pleasantly surprised by what we saw: a strong community, healthy project, lots of big-name companies not only using Solr, but investing in it through adoption, contribution through development/engineering time, etc. If you only follow the news you’d be led to believe Solr is dead and everyone is just flocking to Elasticsearch. That is actually not the case. Elasticsearch being newer, is naturally more interesting to write about. Solr was news 10+ years ago. And of course, there were some people going from Solr to Elasticsearch when Elasticsearch appeared – in the beginning, there were simply no Elasticsearch users.
3. Open source & Licenses
Elasticsearch dominates the open source log management use case – lots of organizations index their logs in Elasticsearch to make them searchable. While Solr can now be used for this, too (see Solr for Indexing and Searching Logs and Tuning Solr for Logs), it just missed the mindshare boat on this one.
Both Elasticsearch and Solr are released under the Apache Software License, however, Solr is truly open-source – Community over code. Solr code is not always beautiful, but once the feature is there it usually stays there and is not removed from the code base. Anyone can contribute to Solr and new Solr developers (aka committers) are elected based on merit if you show your interest and continued support for the project. Also, the committers come from different companies and there is no single company controlling the code base.
On the other hand, Elasticsearch is technically open source, but less so in spirit. Anyone can see the source on Github, anyone can change it and offer a contribution, but only employees of Elastic can actually make changes to Elasticsearch, so you will have to be a part of the Elastic company itself to become a committer.
Moreover, Elastic, the company behind Elasticsearch, mixes code released under Apache 2.0 Software License and code one is allowed to use only with a commercial license. Needless to say, the Elasticsearch user community is not pleased with this. AWS built their own Elasticsearch distribution under the Apache license and bundled a number of features, like alerting, security, etc. You can see Sematext’s review of AWS Open Distribution for Elasticsearch.
A number of organizations have chosen Solr over Elasticsearch as their horses in the search race (e.g. Cloudera, Hortonworks, MapR, etc.) even though they’ve also partnered with Elasticsearch.
Community and Developers
Both Solr and Elasticsearch have lively user and developer communities and are rapidly being developed.
If you need to add certain missing functionality to either Solr or Elasticsearch, you may have more luck with Solr. True, there are ancient Solr JIRA issues that are still open, but at least they are still open and not closed. In Solr world, the community has quite a bit more say even though at the end of the day it’s one of the Solr developers who has to accept and handle the contribution.
Here are a few charts to demonstrate what we mean:
Elasticsearch vs. Solr Contributors click to enlarge
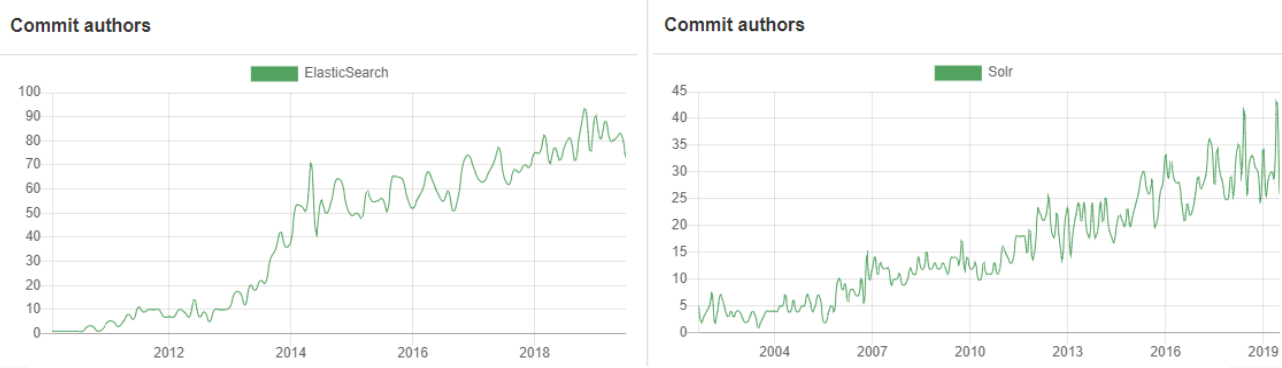
Elasticsearch vs. Solr Commits (source: Open Hub) click to enlarge
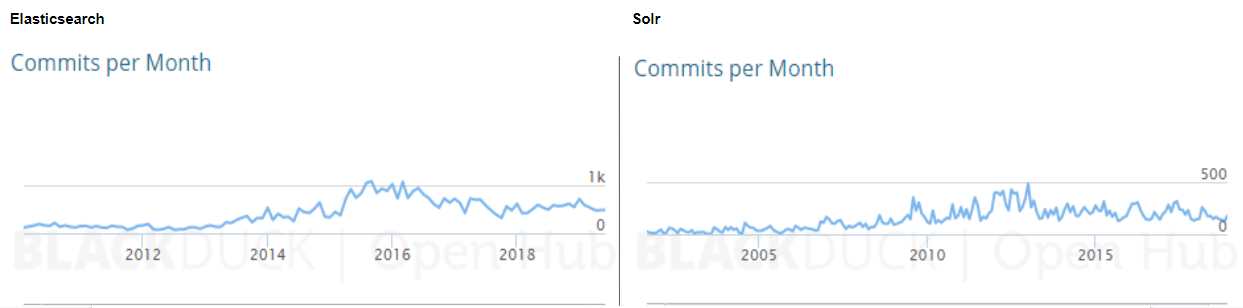
As you can see, Elasticsearch numbers are trending sharply upward, and now more than double Solr Commit activity. This is not a very precise or absolutely correct way to compare open source projects, but it gives us an idea. For example, Elasticsearch is developed on Github, which makes it very easy to merge others’ Pull Requests, while Solr contributors tend to create patches, upload them to JIRA, where they get reviewed by Solr committers before being applied – a less streamlined process. Moreover, Elasticsearch repository contains documentation, not just code, while Solr keeps its documentation in a Wiki. This contributes to higher numbers for both commits and contributors for Elasticsearch.
4. Learning Curve and Support
Elasticsearch is a bit easier to get started – a single download and a single command to get everything started. Solr has traditionally required a bit more work and knowledge, but Solr has recently made great strides to eliminate this and now just has to work on changing its reputation.
Operationally speaking, Elasticsearch is a bit simpler to work with – it has just a single process. Solr, in its Elasticsearch-like fully distributed deployment mode known as SolrCloud, depends on Apache ZooKeeper. ZooKeeper is super mature, super widely used, etc. etc., but it’s still another moving part. That said, if you are using Hadoop, HBase, Spark, Kafka, or a number of other newer distributed software, you are likely already running ZooKeeper somewhere in your organization.
While Elasticsearch has built-in ZooKeeper-like component called Zen, ZooKeeper is better at preventing the dreaded split-brain problem sometimes seen in Elasticsearch clusters. To be fair, Elasticsearch developers are aware of this problem and have improved this aspect of Elasticsearch over the years.
Both have good commercial support (consulting, production support, training, integrations, etc.). Both have good operational tools around it, although Elasticsearch has, because of its easier-to-work-with API, attracted the DevOps crowd a lot more, thus enabling a livelier ecosystem of tools around it.
5. Configuration
Let’s take a quick look at how Solr and Elasticsearch are configured. Let’s start with the index structure.
In Solr, you need the managed-schema file (former schema.xml) in order to define how your index structure, to define fields and their types. Of course, you can have all fields defined as dynamic fields and create them on the fly, but you still need at least some degree of index configuration. In most cases though, you’ll create a schema.xml to match your data structure.
Elasticsearch is a bit different – it can be called schemaless. What exactly does this mean, you may ask. In short, it means one can launch Elasticsearch and start sending documents to it in order to have them indexed without creating any sort of index schema and Elasticsearch will try to guess field types. It is not always 100% accurate, at least when comparing to the manual creation of the index mappings, but it works quite well.
Of course, you can also define the index structure (so called mappings) and then create the index with those mappings, or even create the mappings files for each type that will exist in the index and let Elasticsearch use it when a new index is created. Sounds pretty cool, right? In addition to that, when a new, previously unseen field is found in a document being indexed, Elasticsearch will try to create that field and will try to guess its type. As you may imagine, this behavior can be turned off.
Let’s talk about the actual configuration of Solr and Elasticsearch for a bit. In Solr, the configuration of all components, search handlers, index specific things such as merge factor or buffers, caches, etc. are defined in the solrconfig.xml file. After each change you need to restart Solr node or reload it.
All configs in Elasticsearch are written to elasticsearch.yml file, which is just another configuration file. However, that’s not the only way to store and change Elasticsearch settings. Many settings exposed by Elasticsearch (not all though) can be changed on the live cluster – for example, you can change how your shards and replicas are placed inside your cluster and Elasticsearch nodes don’t need to be restarted. Learn more about this in Elasticsearch Shard Placement Control.
6. Node Discovery
Another major difference between Elasticsearch and Solr is the node discovery and cluster management in general. The main purpose of discovery is to monitor nodes’ states, choose master nodes, and in some cases also store shared configuration files.
When the cluster is initially formed, when a new node joins or when something bad happens to a node \ in the cluster, based on the given criteria, something has to decide what should be done. This is one of the responsibilities of so-called node discovery.
Elasticsearch uses its own discovery implementation called Zen that, for full fault tolerance (i.e. not being affected by network splits), is recommended to have at least three dedicated master node. Solr uses Apache ZooKeeper for discovery and leader election. In this case, it’s recommended to use an external ZooKeeper ensemble, which for fault tolerant and fully available SolrCloud cluster requires at least three ZooKeeper instances.
Apache Solr uses a different approach for handling search cluster. Solr uses Apache ZooKeeper ensemble – which is basically one or more ZooKeeper instances running together. ZooKeeper is used to store the configuration files and monitoring – for keeping track of the status of all nodes and of the overall cluster state. In order for a new node to join an existing cluster Solr needs to know which ZooKeeper ensemble to connect to.
7. Shard Placement
Generally speaking, Elasticsearch is very dynamic as far as placement of indices and shards they are built of is concerned. It can move shards around the cluster when a certain action happens – for example when a new node joins or a node is removed from the cluster. We can control where the shard should and shouldn’t be placed by using awareness tags and we can tell Elasticsearch to move shards around on demand using an API call.
Solr tends to be more static out of the box. By default, when a Solr node joins or leaves the cluster Solr doesn’t do anything on its own. However, with Solr 7 and later, we have the AutoScaling API: we can now define cluster-wide rules and collection-specific policies that control the shard placement, we can automatically add replicas and tell Solr to utilize node in the cluster based on the defined rules.
8. API
If you know Apache Solr or Elasticsearch you know that they expose an HTTP API.
Those of you familiar with Solr know that in order to get search results from it you need to query one of the defined request handlers and pass in the parameters that define your query criteria. Depending on which query parser you choose to use, these parameters will be different, but the method is still the same – an HTTP GET request is sent to Solr in order to fetch search results.
The good thing is that you are not limited to a single response format – you may choose to get results in XML, in JSON in JavaBin format and several other formats that have response writers developed for them. You can thus choose the format that is the most convenient for you and your search application. Of course, Solr API is not only about querying as you can also get some statistics about different search components or control Solr behavior, such as collection creation for example.
And what about Elasticsearch? Elasticsearch exposes a REST API which can be accessed using HTTP GET, DELETE, POST and PUT methods. Its API allows one not only to query or delete documents, but also to create indices, manage them, control analysis and get all the metrics describing current state and configuration of Elasticsearch. If you need to know anything about Elasticsearch, you can get it through the REST API (we use it in Sematext Cloud for logs and events ingestion and retrieval, too).
If you are used to Solr there is one thing that may be strange for you in the beginning – the only format Elasticsearch can respond in JSON – there is no XML response for example. Another big difference between Elasticsearch and Solr is querying. While with Solr all query parameters are passed in as URL parameters, in Elasticsearch queries are structured in JSON representation. Queries structured as JSON objects give one a lot of control over how Elasticsearch should understand the query and thus what results to return.
9. Caches
Yet another big difference is the architecture of Elasticsearch and Solr. Not to get too deep into how the caches work in both products we will only point out the major differences between them.
Let’s start with what a segment is. A segment is a piece of Lucene index that is built of various files, is mostly immutable, and contains data. When you index data Lucene produces segments and can also merge multiple smaller, already existing ones into larger ones during a process called segment merging.
Solr has global cashes, a single cache instance of a given type for a shard, for all its segments. When a single segment changes the whole cache needs to be invalidated and refreshed. That takes time and consumes hardware resources.
In Elasticsearch caches are per segment, which means that if only a single segment changed then only a small portion of the cached data needs to be invalidated and refreshed. We will get to the pros and cons of such an approach soon.
10. Analytics Engine
Solr is large and has a lot of data analysis capabilities. We can start with good, old facets – the first implementation that allowed to slice and dice through the data to understand it and get to know it. Then came the JSON facets with similar features, but faster and less memory demanding, and finally the stream based expressions called streaming expressions which can combine data from multiple sources (like SQL, Solr, facets) and decorate them using various expressions (sort, extract, count significant terms, etc).
Elasticsearch provides a powerful aggregations engine that not only can do one level data analysis like most of the Solr legacy facets, but can also nest data analysis (e.g., calculate average price for each product category in each shop division), but supports for analysis on top of aggregation results, which leads to functionality like moving averages calculation. Finally, though marked as experimental, Elasticsearch provides support for matrix aggregation, which can compute statistics over a set of fields.
11. Full-Text Search Features
Of course, both Solr and Elasticsearch leverage Lucene near real-time capabilities. This makes it possible for queries to match documents right after they’ve been indexed.
The richness of full-text search related features and the ones that are close to full-text searching is enormous when looking into Solr code base.
Our Solr training classes are chock-full of this stuff! Starting from a wide selection of request parsers, through various suggester implementations, to ability to correct user spelling mistakes using spell checkers and extensive highlighting support which is highly configurable.
Elasticsearch has a dedicated suggesters API which hides the implementation details from the user giving us an easier way of implementing suggestions at the cost of reduced flexibility and of course highlighting which is less configurable than highlighting in Solr (though both are based on Lucene highlighting functionality).
Solr is still much more text-search-oriented. On the other hand, Elasticsearch is often for filtering and grouping – the analytical query workload – and not necessarily text search.
Elasticsearch developers are putting a lot of effort into making such queries more efficient (lowering of the memory footprint and CPU usage) at both Lucene and Elasticsearch level.
12. DevOps Friendliness
If you were to ask a DevOps person what (s)he loves about Elasticsearch the answer would be the API, manageability, and ease of installation. When it comes to troubleshooting Elasticsearch is easy to get information about its state – from disk usage information, through memory and garbage collection work statistics to the internal of Elasticsearch like caches, buffers and thread pools utilization.
Solr is not there yet – you can get some amount of information from it via JMX MBean and from the new Solr Metrics API, but this means there are a few places one must look a and not everything is in there, though it’s getting there.
13. Non-flat Data Handling
You have non-flat data, with lots of nested objects inside a nested object and inside another nested object and you don’t want to flatten down the data, but just index your beautiful MongoDB JSON objects and have it ready for full-text searching? Elasticsearch will be a perfect tool for that with its support for objects, nested documents and parent-child relationship. Solr may not be the best fit here, but remember that it also supports parent-child and nested documents both when indexing XML documents as well as JSON. Also, there is one more very important thing – Solr supports query time joins inside and across different collections, so you are not limited to index time parent-child handling.
14. Query DSL
Let’s say it out loud – the query language of Elasticsearch is really great. If you love JSON, that is. It lets you structure the query using JSON, so it will be well structured and give you control over the whole logic. You can mix different kinds of queries to write very sophisticated matching logic. Of course, full-text search is not everything and you can include aggregations, results collapsing and so on – basically everything that you need from your data can be expressed in the query language.
Up until Solr 7, Solr was still using the URI search, at least in its most widely used API. All the parameters went into the URI, which could lead to long and complicated queries. Starting with Solr 7 JSON API part was extended and you can now run structured queries that express your needs better.
15. Index/Collection Leader Control
While Elasticsearch is dynamic in its nature when it comes to shard placement around the cluster it doesn’t give us much control over which shards will take the role of the primaries and which ones will be replicas. It is beyond our control.
Compared to Elasticsearch, in Solr, you have that control, which is a very good thing when you consider that during indexing the leaders are the ones that do more work, because of forwarding the data to all their replicas. With the ability to rebalance the leaders or explicitly say where they should be put we have the perfect ability to balance the load across the cluster, by providing exact information about where the leader shards should be.
16. Machine Learning
Machine learning in Solr comes for free in a form of a contrib module and on top of streaming aggregations framework. With the use of the additional libraries in the contrib module, you can use the machine-learned ranking models and feature extraction on top of Solr, while the streaming aggregations based machine learning is focused on text classification using logistic regression.
On the other hand, we have Elasticsearch and its X-Pack commercial offering which comes with a plugin for Kibana that supports machine learning algorithms focused on anomaly detection and outlier detection in time series data. It’s a nice package of tools bundled with professional services, but quite pricey. Thus, we unpacked the X-Pack and listed available X-Pack alternatives: from open source tools, commercial alternatives, or cloud services.
17. The Ecosystem
When it comes to the ecosystem, tools that come with Solr are nice, but they feel modest. We have Kibana port called Banana which went its own way and tools like Apache Zeppelin integration that allows running SQL on top of Apache Solr. Of course, there are other tools, which can either read data from Solr, send data to Solr or use Solr as the data source – like Flume for example. Most of the tools are developed and supported by a wide variety of enthusiasts.
By comparison, if you look at the ecosystem around Elasticsearch, it’s very modern and sorted. You have a new version of Kibana with new features popping up every month. If you don’t like Kibana, you have Grafana which is now a product on its own providing a wide variety of features, you have a long list of data shippers and tools that can use Elasticsearch as a data source. Finally, those products are not only backed up by enthusiasts but also by large, commercial entities.
18. Metrics
If you love monitoring and metrics, with Elasticsearch you’ll be in heaven. The thing has more metrics than people you can squeeze in Times Square on New Year’s Eve! Solr exposes the key metrics, but nowhere near as many as Elasticsearch. Regardless, having comprehensive monitoring and centralized logging tools like Sematext Cloud – especially when they work seamlessly together like these two do – is essential if you want to have a handle on metrics and other operational data.
Just to sum up, these are the main differences between Solr and Elasticsearch we discussed above:
Top Solr vs Elasticsearch Differences
Feature | Solr/SolrCloud | Elasticsearch |
| Community & Developers | Apache Software Foundation and community support | Single commercial entity and its employees |
| Node Discovery | Apache Zookeeper, mature and battle-tested in a large number of projects | Zen, built into Elasticsearch itself, requires dedicated master nodes to be split brain proof |
| Shard Placement | Static in nature, requires manual work to migrate shards, starting from Solr 7 – Autoscaling API allows for some dynamic actions | Dynamic, shards can be moved on demand depending on the cluster state |
| Caches | Global, invalidated with each segment change | Per segment, better for dynamically changing data |
| Analytics Engine | Facets and powerful streaming aggregations | Sophisticated and highly flexible aggregations |
| Optimized Query Execution | Currently none | Faster range queries depending on the context |
| Search Speed | Best for static data, because of caches and uninverted reader | Very good for rapidly changing data, because of per-segment caches |
| Analysis Engine Performance | Great for static data with exact calculations | Exactness of the results depends on data placement |
| Full Text Search Features | Language analysis based on Lucene, multiple suggesters, spell checkers, rich highlighting support | Language analysis based on Lucene, single suggest API implementation, highlighting rescoring |
| DevOps Friendliness | Not fully there yet, but coming | Very good APIs |
| Non-flat Data Handling | Nested documents and parent-child support | Natural support with nested and object types allowing for virtually endless nesting and parent-child support |
| Query DSL | JSON (limited), XML (limited) or URL parameters | JSON |
| Index/Collection Leader Control | Leader placement control and leader rebalancing possibility to even the load on the nodes | Not possible |
| Machine Learning | Built-in – on top of streaming aggregations focused on logistic regression and learning to rank contrib module | Commercial feature, focused on anomalies and outliers and time-series data |
| Ecosystem | Modest – Banana, Zeppelin with community support | Rich – Kibana, Grafana, with large entities support and big user base |
What about Lucene?
Since both Solr and Elasticsearch are based on Apache Lucene, you may wonder whether using pure Lucene will be better for you. Think of it like this: Lucene is the Linux kernel, while Solr or Elasticsearch is Ubuntu.
You can use the kernel directly and build your own apps on top of it. This will be the option for you if you have a good understanding of the kernel and a narrow use case. Similarly, when it comes to Lucene, Lucene is a search engine library written in Java. You can write your own search engine (in Java) on top of it, and you’ll have full control over what Lucene does.
Like with the kernel example, if you’re not familiar with Lucene, it’s probably going to take a long time and a lot of trial and error. But let’s say you do know Lucene. If you have a wide use case, such as needing to make your search engine distributed, you will probably end up with a solution that does what Solr and Elasticsearch already do.
Both Solr and Elasticsearch expose the most useful – though not all! – Lucene functionality through a REST API. Like Ubuntu does with Linux, Solr and Elasticsearch add their own functionality on top. Things like a distributed model, security, administrative APIs, complex analytics (facets, streaming aggregations) and more. Most use cases need this kind of functionality.
Still not sure which to choose? Check out this video for a little extra help:
So, Apache Solr vs Elasticsearch. Boil it down for me: Which is the best?
This is obviously not an exhaustive list of how Solr and Elasticsearch are different, and certainly not the list intended to tell you which one to choose. We could go on for several blog posts and make a book out of it, but hopefully, the below list will give you an idea about what to expect from one and the other so you can put it in perspective based on your needs.
Still undecided? Find out how Elasticsearch compares with OpenSearch, another option you may consider. You should also check our list of the best small search platform alternatives to get the full picture.
We offer Solr Monitoring agent that helps to monitor all key metrics and provides out-of-the-box charts that make it easier to spot issues.
Check Solr monitoring See plans
Free for 14 days. No credit card required.
In conclusion, here are the bits that we think make the most difference for anyone having to make a choice:
- If you’ve already invested a lot of time in Solr, stick with it, unless there are specific use cases that it just doesn’t handle well. If you think that is the case, speak to somebody close to both Solr and Elasticsearch projects to save you time, guessing, research, and avoid mistakes.
- If you are a strong believer in true open source, Solr is much closer to that than Elasticsearch, and having one company control Elasticsearch may be a turn-off.
- If you need a data store that can handle analytical queries in addition to text searching, Elasticsearch is a better choice for that today,especially because of the availability of the bigger ecosystem.
Elasticsearch Monitoring agent correlates metrics, anomalies, alerts, events, and logs to make it easier for you to troubleshoot performance issues.
Check Elasticsearch monitoring See plans
Free for 14 days. No credit card required.
Want to learn more about Solr or Elasticsearch?
If you need any help with Solr / SolrCloud or Elasticsearch – don’t forget that we provide Solr & Elasticsearch Consulting, Solr & Elasticsearch Production Support, and offer both Solr & Elasticsearch Training.
And don’t forget to download the Cheat Sheet you need. Here they are:
 Solr Node, Jetty, JVM Metrics and more…
Solr Node, Jetty, JVM Metrics and more…Solr Metrics API Cheat Sheet
 Useful DevOps snippets on Allocation, Caches, Merges, Troubleshooting and more…
Useful DevOps snippets on Allocation, Caches, Merges, Troubleshooting and more… Elasticsearch DevOps Cheat Sheet
Then, subscribe to our blog or follow @sematext.