This article is the third of a four-part series of articles about Elasticsearch monitoring. In the first article, we put together an Elasticsearch guide, covering how Elasticsearch works and why the setup and tuning of Elasticsearch requires a good knowledge of configuration options and performance metrics.
In this article, we’re going to discuss some of the Elasticsearch open-source monitoring tools which can help with monitoring your Elasticsearch cluster. We’re also going to talk about the benefits and pitfalls of using an Elasticsearch open-source monitoring solution to monitor your Elasticsearch cluster. They may not have full-blown features like Sematext Elasticsearch monitoring integration or other SaaS tools, but keep in mind they’re open-source products and can hold their own just fine.
In the last part of this 4-part series, we’ll explore how to monitor Elasticsearch with Sematext.
If you’re looking for more direct help, keep in mind that Sematext offers a full range of services for Elasticsearch.
Or, if you’re just looking for some more details on Elasticsearch, check out this short video on Elasticsearch metrics to monitor:
Characteristics of a Good Elasticsearch Monitoring Tool
Before we review monitoring tools, let’s establish a baseline of the features a proper monitoring tool should include. The first thing is that a tool should be easy to install, configure and maintain. An Elasticsearch monitoring tool should be able to gather all of the following metrics:
- System metrics, such as memory, CPU, and disk reads and writes.
- JVM metrics like heap usage, pool size, and garbage collector performance.
- Elasticsearch-specific metrics like request latency, indexing rate, merges and refreshes, cluster health, and node availability and usage.
Once the tool has gathered these metrics, we need it to leverage them to provide:
- Visual indicators of system health through dashboards and graphs
- Automated monitoring of health with anomaly detection and alerting of undesirable behavior
- Integrations with communication systems like Slack, and incident management systems like PagerDuty.
Of all the features mentioned above, automation is the most important. Delegating the task of monitoring your clusters to a tool frees you and your engineers to focus on innovating and improving your software offerings, trusting that your monitoring tool will notify you if you need to resolve any problems with your cluster.
Popular Elasticsearch Monitoring Tools
We’re going to look at some of the most popular open-source monitoring tools available for use today, and compare them against the characteristics we listed above. Specifically, we’re going to review:
- Elastic Monitoring with the Stats API and Kibana
- Elasticsearch HQ
- Kopf & Cerebro
- ElasticSearch Head
Elasticsearch Monitoring with Kibana
Elasticsearch is the primary data source component in a collection of products called the Elastic Stack. Each component within this stack is responsible for monitoring itself and reporting the results to the Elasticsearch cluster which is responsible for monitoring. It is advisable to collect metrics in a different cluster, especially if you’re operating an Elasticsearch cluster in production.
Elasticsearch has a comprehensive API which you can query, and receive information about the health of the cluster, nodes, and tasks. The endpoints you can call and example queries and responses are well-documented in the Elasticsearch Reference.
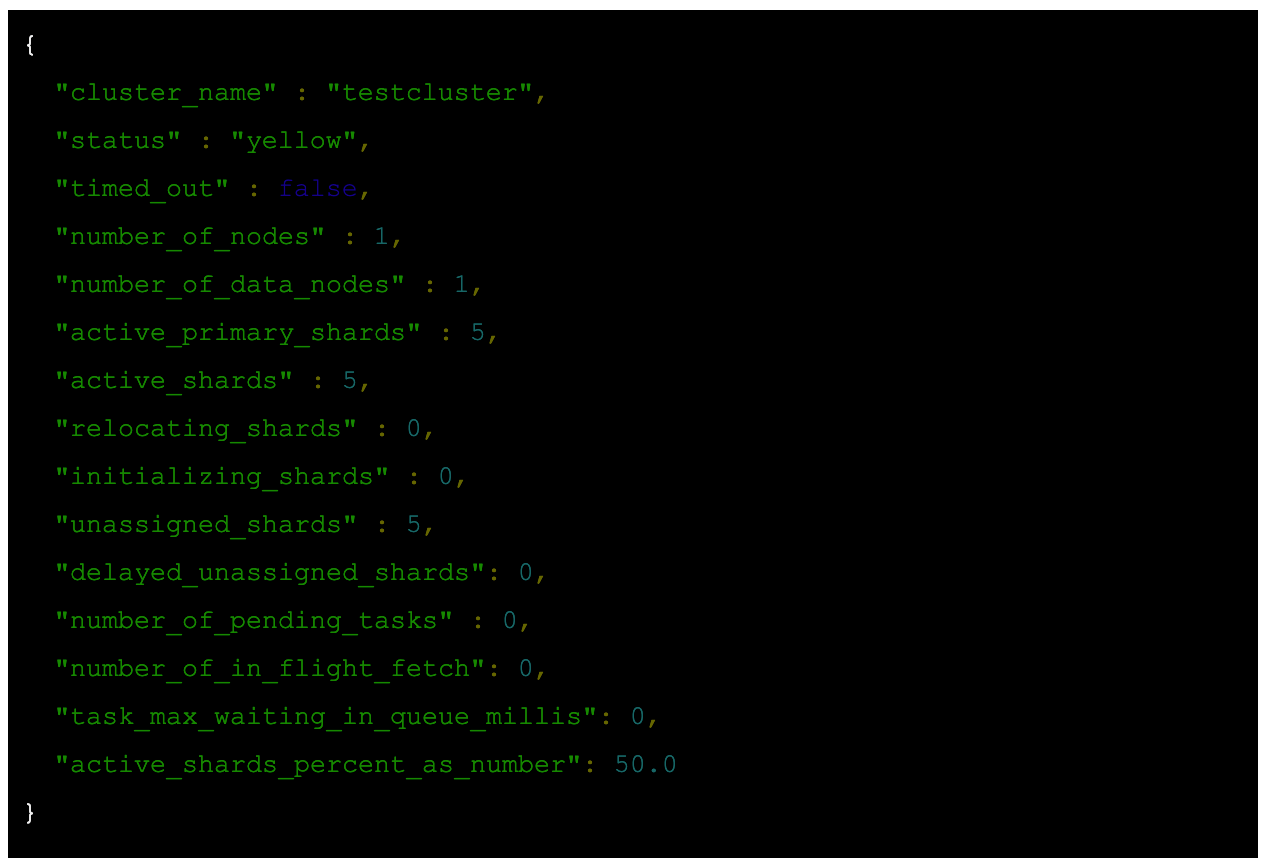 Fig. 1. Example of Response to a Request Sent to GET _cluster/health
Fig. 1. Example of Response to a Request Sent to GET _cluster/health
If you’re not entirely comfortable handling JSON responses, the Elastic team also provides a collection of cat APIs which provide similar data, but in a more user-friendly format. These are well-documented here.

Fig. 2. Example of Response to a Request Sent to GET /_cat/allocation?v
Elastic Stack Features (formerly X-Pack) is the current Elastic extension which handles monitoring of the stack, along with other functions such as security, alerting and reporting. X-Pack was originally released as a premium product with a combination of free and paid features. In 2018 Elastic made the decision to open the code base for X-Pack under the Elastic license, and while features like monitoring remain free, other features still require you to purchase a license before using them. Alternatively, you can also investigate some Elastic Stack Features (formerly X-Pack) alternatives.
Before you install X-Pack, you’ll need to have Elasticsearch, Kibana and any other Elastic components which you plan on using. Installing X-Pack with Elasticsearch is well-documented in the Elastic documentation. Among the installation steps required are: configuring security protocols, restart your cluster, and setting up password access.
Once you have X-Pack fully configured, you can then surface the reported metrics on a Kibana dashboard. Kibana provides a platform to build crisp visualizations and set up alerts and watches to let you know when your metrics begin to indicate problems with the cluster. You can learn more about setting up dashboards in the Elastic documentation.
ElasticHQ / Elasticsearch HQ
ElasticHQ is an open source Elasticsearch monitoring solution which was started by Roy Russo, co-author of Elasticsearch in Action. The tool is available from GitHub as a Python-based project, or as a Docker Image from Docker Hub.
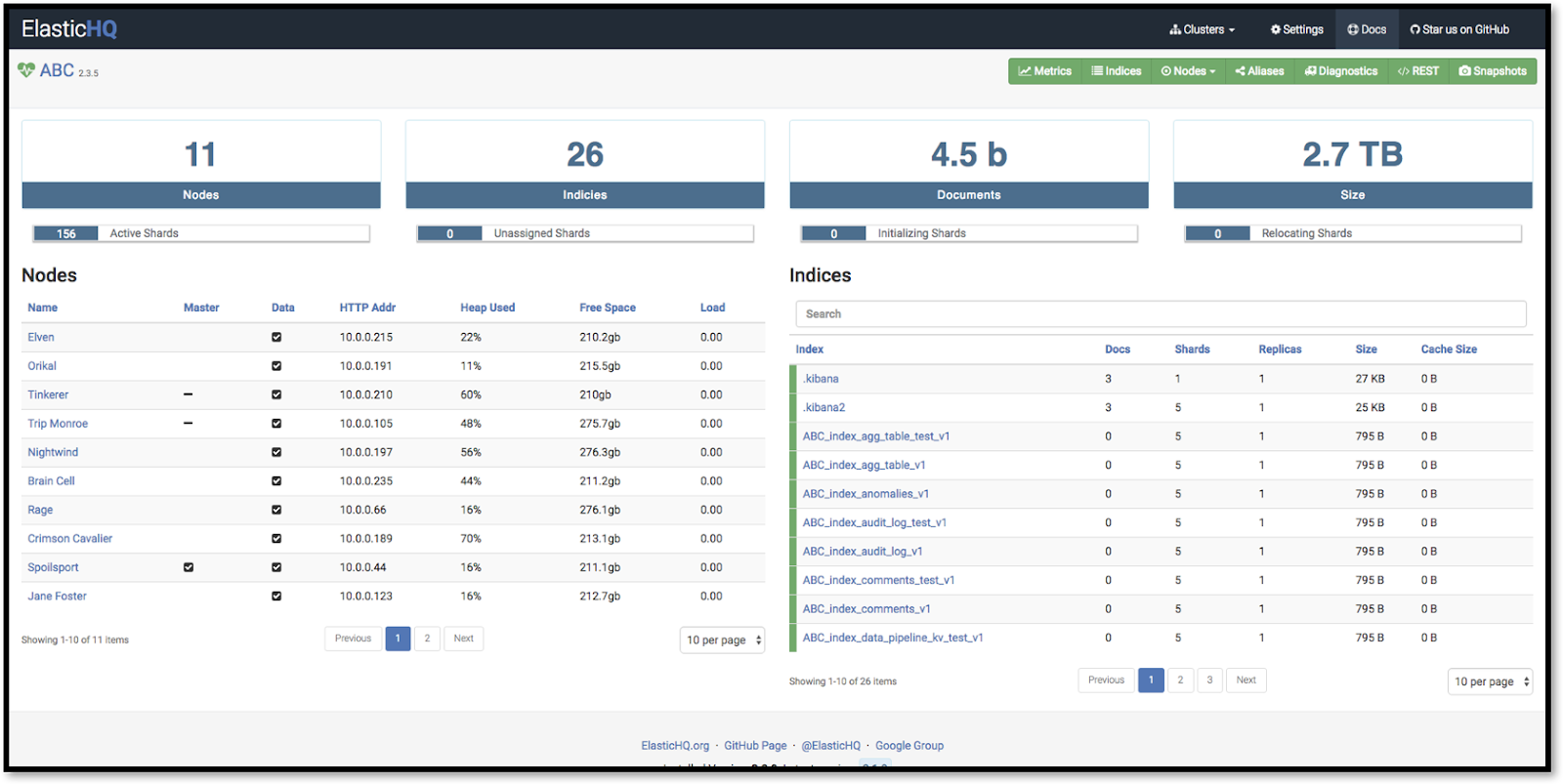
Fig 3. ElastiqHQ Dashboard from github.com/ElasticHQ/elasticsearch-HQ
The project website features elementary documentation, and recommends that users post questions, problems, and bugs to the GitHub Issue Tracker for the project. Overall, the tool is very functional and provides users with simplified access to the health and cat APIs available directly on the Elasticsearch cluster.
The project is actively maintained and is updated on a regular cadence. One potential security concern identified in the documentation is that the username and password to access the Elasticsearch cluster is stored in plain text within the ElasticHQ database. This enables faster connections to the cluster but will cause heartburn among those responsible for securing your environments.
Elasticsearch Kopf and Cerebro
In early Elasticsearch-related blogs and articles, Elasticsearch Kopf features prominently as an open source monitoring option. Unfortunately, the project only supports Elasticsearch through version 2.0 and hasn’t been updated since the end of 2015.
As the next iteration, Cerebro supports later versions on Elasticsearch. The project is available from its GitHub repository. The project requires the Java 1.8 runtime and was written using a combination of Scala and Angular.
Documentation for the project is limited to the README page, which specifies how to get the tool running, and how to build and run a Docker image with the same. At the time of writing, the last stable release was in June of 2018.
ElasticSearch Head
Our final open source utility is ElasticSearch Head. This utility is available on GitHub and is regularly maintained and updated. The tool is written with Node.js and can be run in the following forms:
- Built-in server
- Docker
- Chrome extension
When compared with the previous two utilities, this project sees more updates and greater community participation. The project organizer also provides a basic website with installation instructions and an assortment of screenshots.
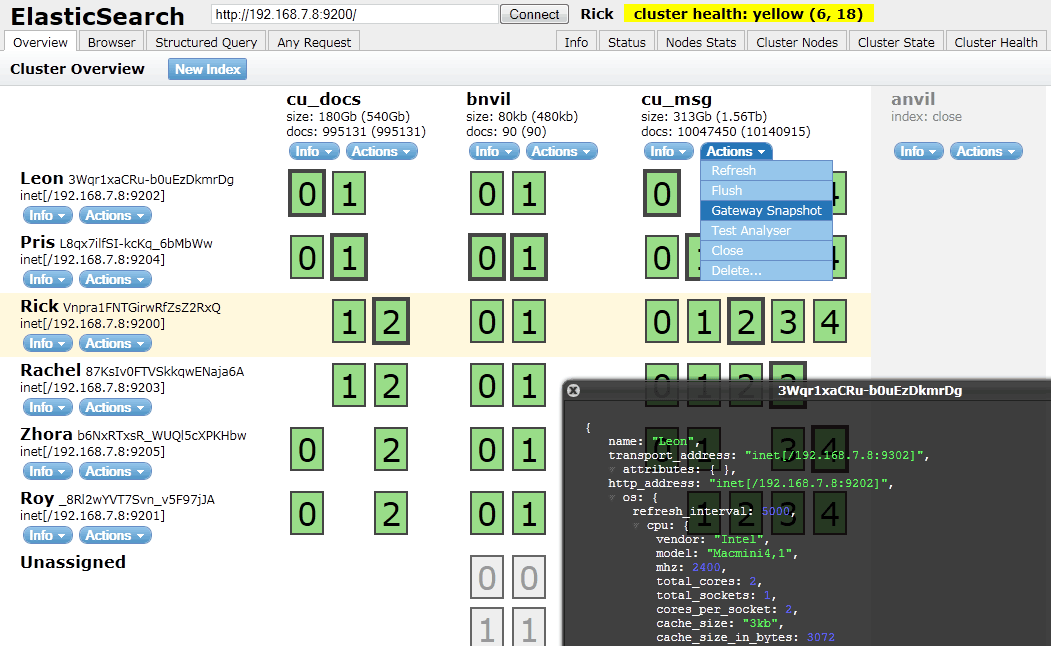
Fig 4. ElasticSearch Head Dashboard from mobz.github.io/elasticsearch-head/
Pros and Cons of Open Source Tools
From the perspective of initial investment, adopting an open source solution seems to be a no-brainer. Once you have the tool installed, you are dependent on the community for support. Thus, this dependency can bring mixed results. Often, open source solutions end up costing an organization more in the long-term because they need to devote development resources to resolve problems, or hiring outside help for the same. This increases the actual total cost of ownership and organizations regularly underestimate it.
Open source software also has the potential to provide enhanced reliability and improved security because of the vast talent pool which is collaborating to improve and enhance the project. Unfortunately, not all open source projects receive the same attention or scrutiny, and often in the face of limited community participation, fall into a state of atrophy and disrepair.
Conclusion
Selecting a monitoring tool which can effectively monitor your Elasticsearch helps you better maintain your Elasticsearch clusters and ensure they remain healthy and performant for your users. Open source tools come with a budget-friendly price tag but may also introduce problems and additional maintenance overhead into your organization.
About the Author

Mike Mackrory is a Global citizen who has settled down in the Pacific Northwest — for now. By day he works as a Lead Engineer on a DevOps team and by night he writes and tinkers with other technology projects. When he’s not tapping on the keys, he can be found hiking, fishing and exploring both the urban and rural landscape with his kids. Always happy to help out another developer, he has a definite preference for helping those who bring gifts of gourmet donuts, craft beer and/or single-malt Scotch.