Cloud-Based Database Monitoring
Monitor, alert, and report on database performance metrics with our open-source monitoring tools, whether running on your own infrastructure or public cloud.
Case Studies

CoEnterprise
...by far the best-priced "OOTB" logging solution we found

BlockGen (Stratumsphere)
Sematext just worked as we wanted it to, end of story....we are glad we found it
 Zach Aufort, BlockGen CEO
Zach Aufort, BlockGen CEO

iQmedia
We gained valuable insight into usage of our processes in addition to precisely knowing the location of processes without going to a manually maintained map

Pygmalios
Combining server monitoring with Docker container monitoring and logging was the product feature we found most helpful
 Ján Antala, Pygmalios VP Engineering
Ján Antala, Pygmalios VP Engineering

UALA
...it is the ideal monitoring tool for our infrastructure

Fenom Digital
...Sematext provided the perfect balance of full-featured functionality combined with transparent pricing
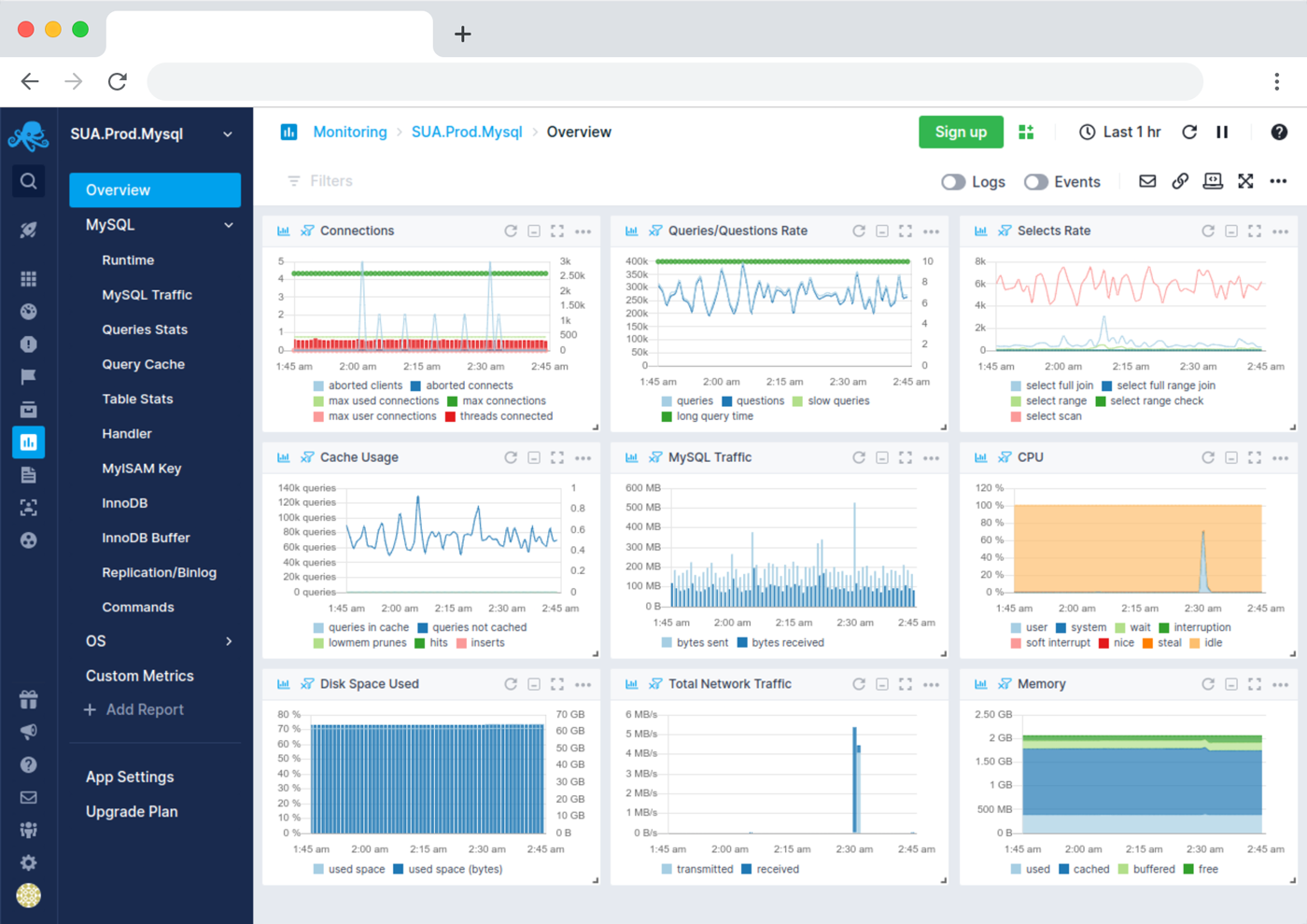
Relational Database Monitoring
Detailed AWS RDS, AWS Aurora, PostgreSQL, MySQL and MariaDB performance statistics, including MyISAM and InnoDB engine metrics.
- Get SQL select or sort usage stats
- View access and connection performance details (used connections, aborted clients…)
- Get alerted on database metrics for tables, handles, threads, open files, cache usage, etc.
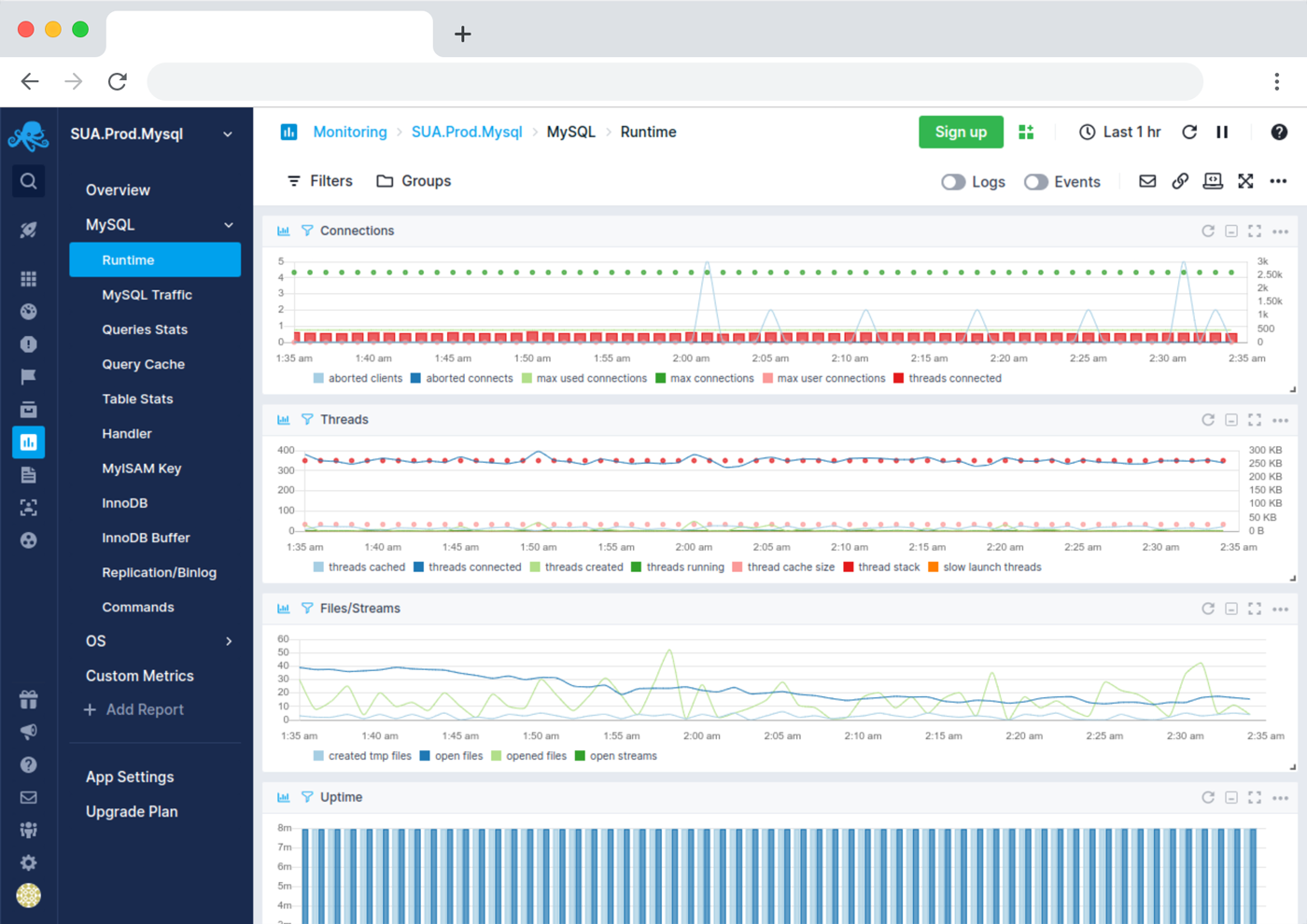
Monitor Database Performance in Real Time
Get insights into performance issues in real time and stay in control with our database monitoring software.
- Understand traffic in and out of database
- See performance and specific database statements being executed database queries/questions details
- Monitor database slow queries count and wait events
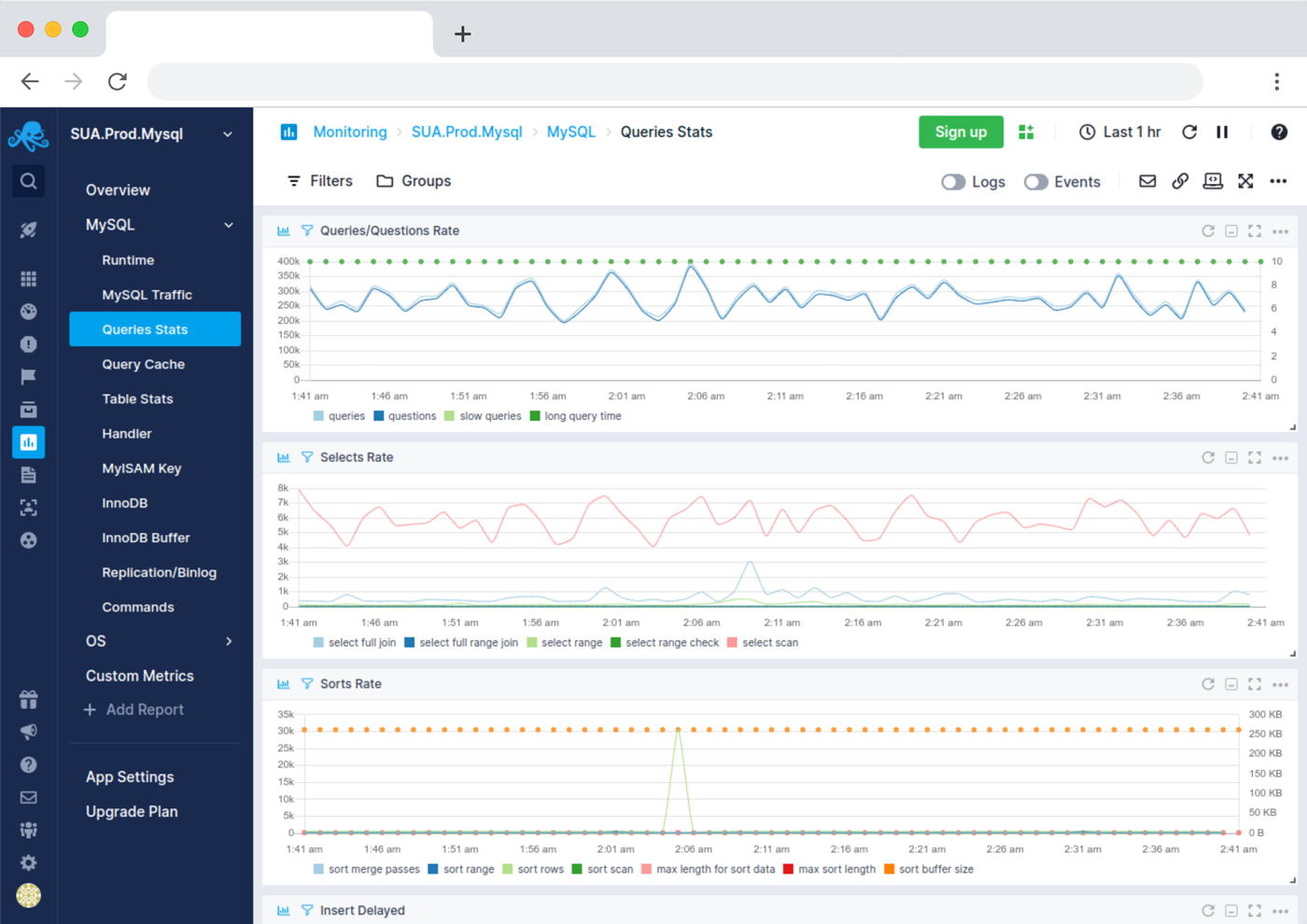
Open-Source Database Monitoring Agent
Sematext collects health metrics from a variety of databases and other sources in an easy, fully pluggable way.
- Out of the box integrations for monitoring MySQL, PostgreSQL, Cassandra, Elasticsearch, Solr, ClickHouse, MongoDB, and others
- Extensible agent integrations let you create new monitoring integrations without any coding
Supported Database Technologies
Relational/SQL Databases






NoSQL Databases




Search Engines


Database Performance Monitoring in One Single Dashboard
Monitor all your databases in a unified view. Correlate database performance data with application metrics, logs, and traces for faster troubleshooting.
- Sematext Agent automatically discovers your databases and their logs
- Use out-of-the-box dashboards and alert rules and create your own
- Easily pivot from viewing performance metrics to troubleshooting logs
- View application and database performance metrics in a split view for each correlation